Authors note: The following article is based on the experience of building out a Kubernetes deploy in AWS for a very large, high volume web workload. Statements made may not apply to your situation, but should give you guidance on why Ingress is awesome, and how to get the most out of Traefik. Please apply some common sense. You’re smart after all right?
So you built a Kubernetes Cluster on AWS using say KOP’s or EKS. Next you want to start deploying your groundbreaking Web service which will make you a fortune right? But how to expose those Kubernetes Service to the outside world, Ingress or Load Balancer?
Well the easy answer would be create a Service resource of type LoadBalancer and let Kubernetes handle creating the Load Balancer in AWS. Now you can sit back and bask in your glory right? Well not quite yet. There are a couple of issues with the way Kubernetes handles Services of type LoadBalancer on AWS.
The first issue is that it will create a Classic Load Balancer (Aka ELB in old parlance) which are really considered superseded buy the more feature rich Application Load Balancer. The second issue is that for every Service you created of type LoadBalancer you create a new Classic Load Balancer which you will have to pay for. Not great right (unless you have shares in Amazon of course)?

So what’s the answer? Well as the title suggests Kubernetes has the concept of a Ingress resource. In brief Ingress works like a reverse proxy to allow you to route traffic to a single end point and use things like HTTP headers to route the traffic to the right Kubernetes Service by means of rules. More details on Ingress can found in the doc (here).
Now we are going to look at deploying Traefik to act as our ingress controller, and route traffic to it via an ALB. Note that this article won’t give you resource yaml, but it is heavily based on the stable/traefik helm chart but with some tweaks.
The Traefik documentation makes the very sensible suggestion: If you are unsure which to choose, start with the Daemonset.
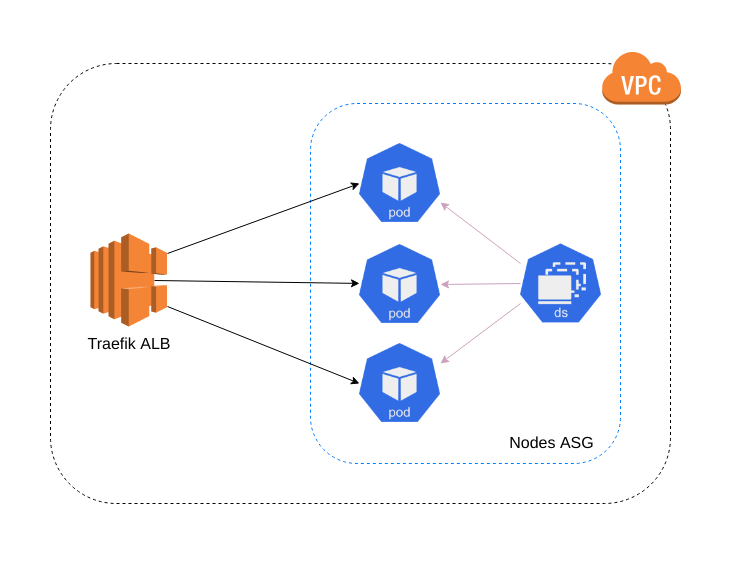
The above diagram shows whats this would look like with a Daemonset running Traefik on all the nodes in an Autoscaling group. Then an Application Load Balancer can be deployed at point at the Autoscaling Group. By using a DaemonSet we are also nicely scaling so as you add more nodes to the cluster, the Daemonset will make sure Traefik is running on every node (and of course make sure it stays running).
We can combine running Traefik as a DaemonSet with expoisng the service via a NodePort which means each container binds its exposed port to a high numbered port on the host. So in this example if running Traefik on port 80, we could map that to port 30080 on the host and point the Target group configuration at that. The same approach can be used on the dashboard port which is normally 8080.
This means that a customer can go to port 443 on your ALB, which connects to NodePort which matches to Traefik which in turn maps to our service. Tada!
As mentioned, a DaemonSet is like a deployment but is special in that rather than specify a number of pods to be running rather you state that it should be running on all nodes (or a subset via a selector). This means that we also gain a high level of redundancy in that there will also be multiple pods running. It also means that as the ALB round robins over the nodes it will always have a Traefik pod to connect to without kube-proxy having to proxy the request to another node in the cluster. No extra hops required. Woohoo!
There a few other considerations you need to make when deploying Traefik on to Kubernetes. First off Traefik works as a cluster which means someone has to be in charge. This is done via an election process and the result stored in a Key/Value store. Traefik is great in that it supports loads of backends for this including Consul, DynamoDB and ECTD. It’s worth noting that if you are using KOPs (or I suspect but not checked EKS) that ECTD is configured such that is only accessible by the Kubernetes API pods so you will need to use another Key/Value store. Consul worked well for one customer, but DynamoDB also looks good (and Consul on Kubernetes makes me a tad nervous, but this may change my mind.) but at time of writing I haven’t used it.
The other key thing when thinking about anything that will go into Production is Metrics. Who doesn’t love a graph? Traefik has great support Prometheus (I really recommend the excellent stable/prometheus helm chart) and exposes data for both overall and at a per backend/service point, including connection count and error counts. So as you can see by using an Ingress controller you can give yourself a huge amount of flexibility while still maintaining control over your costs, while Traefik makes deploying and observing your Ingress rules very simple. So your happy and Mr Bean Counter is happy. It’s a Win Win!